Google ColaboratoryというGPUを無料で使えるサービスを使って画像認識させてみたいなと思ったので実際にやってみました。
日本語の情報はまだ少ないようなので少し苦労しましたがなんとかできました。
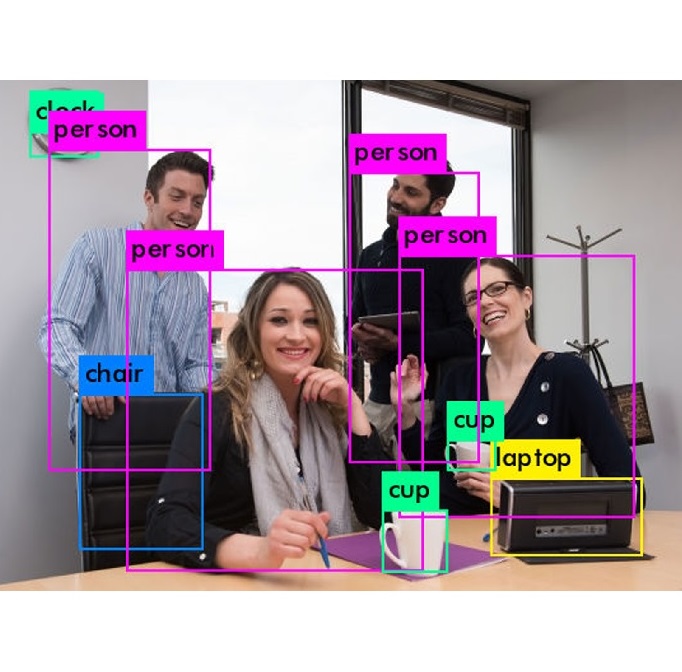
Colab上で画像認識させてみた結果がこちら。
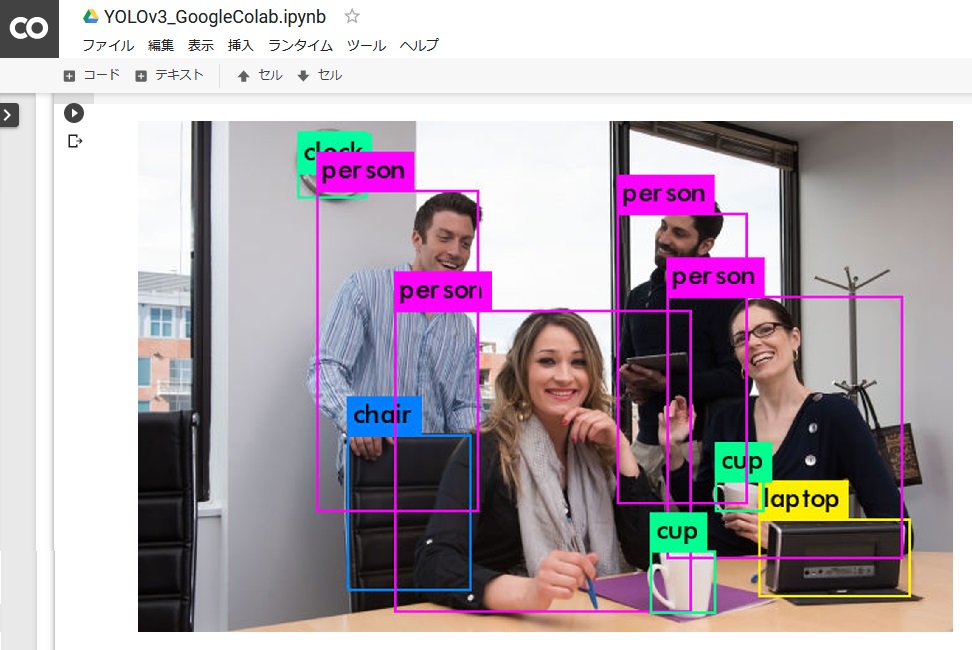
人もコップも椅子も時計も全て認識してくれています。うん、いい感じです。
Google Colaboratory上の環境はこちらのページの通りに実施したらできました。ありがたやありがたや。今回は「darknet」というフレームワークを使用していますが、「Keras」を使用して動かす方法もあるようです。
※以下のリンクではCUDA8.0をインストールするとなっていますが、この部分についてはインストールせずに既にインストールされている最新のCUDAをそのまま使用したほうがよさそうです。(2020/1/20追記)
GitHub – ivangrov/YOLOv3-GoogleColab
手順の最後のほうになったら「upload():」を実行して自分のローカルPCのから画像をアップロードさせます。
画像がアップロードされたら以下のコマンドを実行して画像認識させてみましょう。今回は「BusinessPerson.jpg」という画像を処理してみます。
|
1 |
!./darknet detect cfg/yolov3.cfg yolov3.weights BusinessPerson.jpg |
認識させたら次に以下のコマンドで表示させてみましょう。ファイル名の「predictions.jpg」は変更せずに実行してください。
|
1 |
imShow('predictions.jpg') |
そしたら自分がアップロードした画像の処理後の画像が表示されるはずです。私は以下の画像を認識させてみました。
動画を処理する場合は、同様に動画をアップロードしてから以下のコマンドを入力します。
|
1 |
!./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -dont_show test.mp4 -i 0 -out_filename fiddlevideo1.avi |
ローカルPCではCPUでやっていたのでこちらのほうが宇宙倍早かったです。
宇宙倍は言いすぎかもですが、体感としては100倍ぐらい違うんじゃないですかね。処理が終わったら以下のコマンドで動画をローカルPCにダウンロードします。
|
1 |
download('fiddlevideo1.avi') |
ダウンロードした動画がこちらです。
日本語の情報が少ないので増えていったら嬉しいなとか思ったりしますね。









コメントを残す