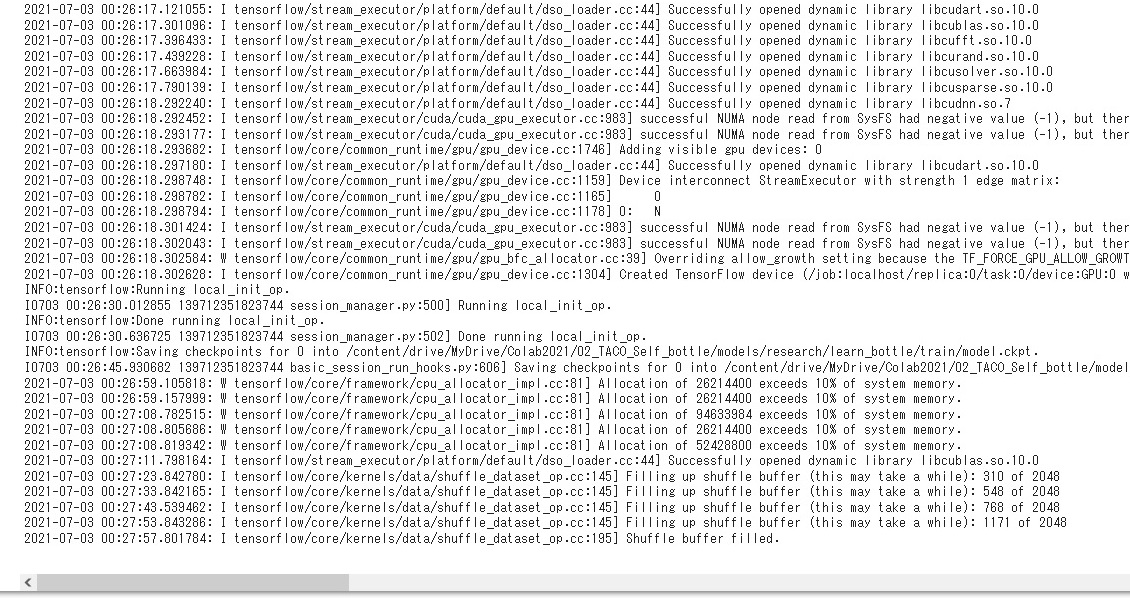
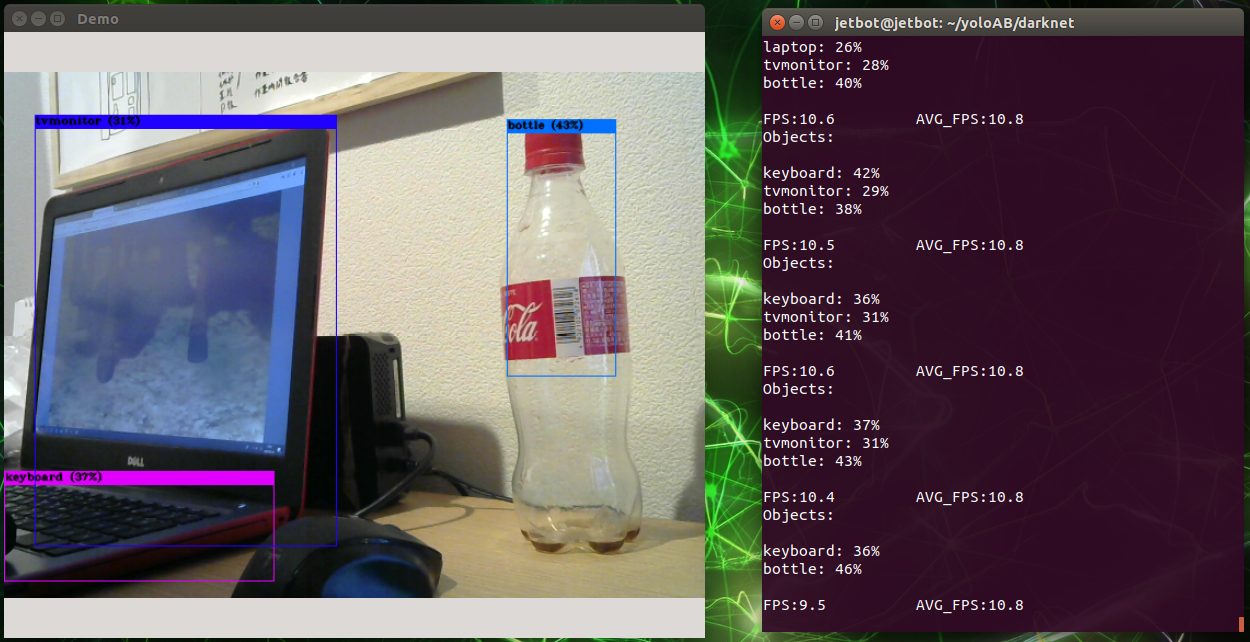
tensorflow 1.15.0でRetrain SSD MobileNet V1 detector for the Edge TPU (TF1) を試しているときにこちらのエラーが発生して強制終了してしまいました。
|
1 2 3 4 5 |
2021-07-03 08:21:23.813619: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0 2021-07-03 08:21:35.070195: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:145] Filling up shuffle buffer (this may take a while): 424 of 2048 2021-07-03 08:21:45.075358: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:145] Filling up shuffle buffer (this may take a while): 875 of 2048 2021-07-03 08:21:50.048099: I tensorflow/core/kernels/data/shuffle_dataset_op.cc:195] Shuffle buffer filled. ./retrain_detection_model.sh: line 58: 1360 Killed |
こちらの記事に対応方法が載っていました。どうやら大きいサイズのデータをトレーニングすると上記の状態になってしまうことが多いようです。
Tensorflow object detection API killed – OOM. How to reduce shuffle buffer size?
上記の記事によると「batch_size」と「shuffle_buffer_size」のサイズを小さくしてあげるといいようでした。「shuffle_buffer_size」は以下のファイルで「default = 2048」となっています。
・models/research/object_detection/protos/input_reader.proto
|
1 |
optional uint32 shuffle_buffer_size = 11 [default = 2048]; |
「batch_size」と「shuffle_buffer_size」の値を変更するために以下の手順を実施します。
・models\research\learn_bottle\ckpt\pipeline.config
① batch_sizeの値を小さくする。自分の場合は「batch_size: 5」にしました。デフォルトは「batch_size: 128」になっています。
|
1 2 3 4 5 6 7 8 9 10 |
train_config { batch_size: 5 data_augmentation_options { random_horizontal_flip { } } data_augmentation_options { ssd_random_crop { } } |
② shuffle_buffer_sizeを挿入します。自分の場合は「shuffle_buffer_size: 1024」を挿入しました。これを設定しない場合、デフォルトでは「2048」が設定されてしまいます。
|
1 2 3 4 5 6 7 |
train_input_reader { shuffle_buffer_size: 1024 label_map_path: "/models/research/learn_bottle/bottle/pet_label_map.pbtxt" tf_record_input_reader { input_path: "/models/research/learn_bottle/bottle/pet_faces_train.record-?????-of-00010" } } |
③ コンパイルして①と②の設定を反映する
・models/research/ に移動する
|
1 |
protoc object_detection/protos/*.proto --python_out=. |
これで解決できました。





コメントを残す